Note – I originally posted this here on the NHS Choices blog back in February. It was written as three separate posts about User Research, from the point of view of someone who hasn’t been involved in this kind of thing before.
Over the last fortnight I’ve been observing User Research with my team, and it has been quite an eye-opener.
We’re at the point in our Discovery phase where we’ve made a bunch of assumptions about our users and their needs, and gathered information around these assumptions from various sources – on and off-site analytics, existing literature and research, social media, our service-desk tickets, and on-site surveys.
Now it’s time for us to talk directly to some USERS*
* Not all of the people we interview are necessarily users of the current NHS Choices service. Some of them might be potential users too.
User Research like this isn’t new to us. NHS Choices has had a dedicated Research team since 2007, but it’s in the last year or so that we’ve really started to more tightly integrate the work that the researchers do, into our delivery cycle. This is the first time we’ve involved the whole of the multi-disciplinary transformation team in observing and note-taking for the research sessions, doing the analysis and deciding on next steps within a couple of intensive research days.
Who do we interview?
For the two topics we’re focusing on right now – we’ve been talking to two distinct groups of people
- Parents of children who’ve had Chickenpox in the last three months
- People who sought a new Dentist in the last three months
We make sure we talk to a mixture of men and women from different socio-economic groups, of different ages, and with differing levels of internet skill.
We ask some quite detailed questions, so it’s good to get people who have had a relatively recent experience (hence the three month time-window) as the experiences they’re recalling will tend to be more accurate.
We use some dedicated participant recruitment agencies to source the specific people we want to interview. We supply a spec, like the parents described above, and they go and find a selection of those people. Obviously there’s a cost attached to this service, but the recruitment can be time-consuming, and it would be difficult to find a big enough cross-section of people ourselves. Outsourcing this to an agency frees up our researchers to focus on the actual research itself.
The setup
We do some interviews in the participants’ own homes – interviewing people in their own environment gives us a much better sense of how people look for information and where this fits into their lives. Also we get to meet participants who would not want to go to a viewing facility.
We also do interviews in a dedicated research facility – these are the ones that the rest of the team and I have been observing.
We’ve used a couple of facilities so far, one in London, and SimpleUsability in Leeds – just a five minute walk from our Bridgewater Place office.
Our interviews have been one hour long. The participants sit with a researcher – who conducts the interview – and a note-taker in the interview room. The note-taker might be another researcher or other member of the team – we’ve had UX Architects and service desk analysts taking notes in our sessions.
With the participants, the researcher and the note-taker in the interview room, the rest of the team are behind a one-way mirror with the sound piped in, observing the whole show.

And yes, with the one-way mirror, it fell to @seashaped and myself to make all the obligatory unfunny gags about being in a police interrogation scenario…
Interviewing
The interviews are based around a Topic Guide prepared beforehand by the researcher. This is based on input from our previous research, and includes specific subjects around which we want to learn more. The whole team feeds their ideas into the Topic Guide.
The interviews aren’t run strictly to the guide though – we’re talking to people about their lives, and the health of them and their families, so naturally the discussion can wander a little. But our researchers are great at steering the discussion such that we cover everything we need to in the interviews.
We decided not to put any prototypes in front of users in the first round of research. We’re trying to learn about users’ needs and their state of mind as they’re trying to fulfil those needs, so we didn’t want to bias them in any way by putting pre-formed ideas in front of them.
We did run a card-sorting exercise with users in the first round of Dental research – getting the participants to prioritise what would be most important to them when searching for a new dentist, by letting them sort cards.
We had a camera set up for the card-sorting exercise, so we could all see it clearly, without crowding around the mirror in the observation room.

As the interview takes place, the note-taker is busy capturing all of the insights and information that come up. As the participant talks, the note-taker captures each individual piece of information or insight on a separate post-it note. This results in a lot of post-its – typically we’ve been getting through a standard pack of post-its per interview.
GDS have written in more detail about some note taking good practices.

Sorting into themes
Once the interviews are over, we have to make sense of everything the users have told us. We have a whole load of insights – each one logged on an individual post-it note. We need to get from what the users have said, to some actionable themes, as quickly as possible, without producing heavyweight research reports. We use the affinity-sorting technique to help us do this.
This basically involves us sorting all of the post-its into themes. We’ve been having a stab at identifying themes first, and then sorting the post-its into those groups first. As the sort takes place we’ll typically find that a theme needs to be split into one or more themes, or sometimes that a couple of existing themes are actually the same thing.

This isn’t the job of just the researcher and note taker who conducted the interviews. The whole team that’s been carrying out and observing the User Research takes part in this process, shifting post-its around on the wall until we feel we have some sensible groupings that represent the main themes that have come out of the interviews.


Although we’re not presenting our research findings as big research reports or presentations, we are logging every insight electronically. After the sort, every insight gets logged in a spreadsheet with a code to represent the participant, the date and the theme under which the insight was grouped. We’re reviewing our approach to this, but the idea is that over time this forms our evidence base, and is a useful resource for looking back over past research, to find new insights.
Hypotheses
Once we have our themes we have to prioritise them and decide what to do with them next. At this early stage this usually means doing some more learning around some of the important themes. We’ve been forming Hypotheses from our Themes – I think this helps to highlight the fact that we’re at a learning stage, and we don’t know too much for sure, just yet.
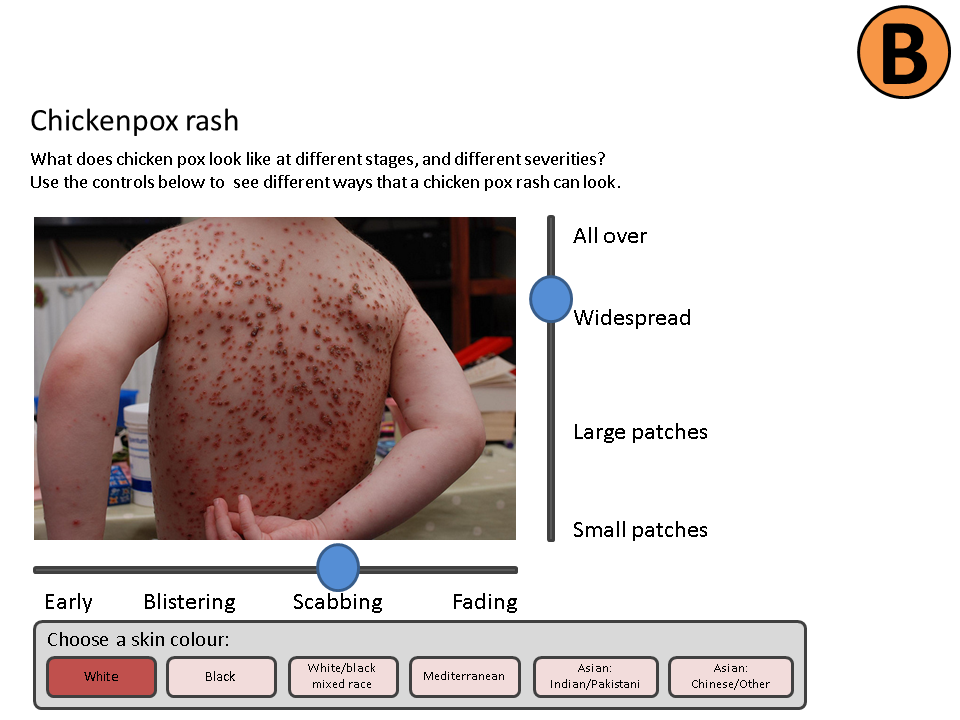
We’ve been playing around with the format of these Hypotheses. As an example, one of the strong themes from our first round of User Research on Chickenpox was around visual identification. We expressed this as follows –
We believe that providing an improved method of visual identification of Chickenpox
for parents
will achieve an easier way for parents to successfully validate that their child has Chickenpox.
When testing this by showing a variety of visual and textual methods of identification to parents of children who’ve had chickenpox
we learned …
So we will…
If you’re familiar with User Stories, you can see how this hypothesis would translate into that kind of format too. You could argue that all User Stories are Hypotheses really, until they’re built and tested in the wild.
Low-fidelity Prototypes
In order to test this hypothesis, we’re going to need some form of prototype to put in front of users. We’re working on a weekly cycle at present so we only have a few days before the next round of research. Speed of learning is more important at this stage, than how nice our prototypes look, so we’re just producing really low-fidelity prototypes and presenting them on paper.
For the visual identification hypothesis, here are some of the prototypes we’re presenting to users in our second round of research – see what I mean by low-fidelity, but this is just what we needed in order to explore the concepts a bit further, and learn a bit more.

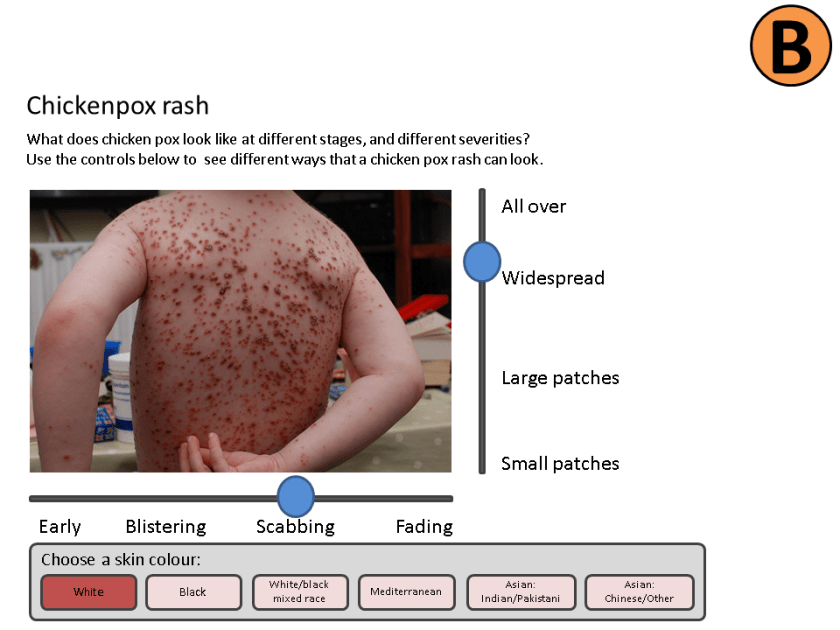
We’ll base some of the questioning in our second round of research around these prototypes, and capture what we learn in our hypothesis template.
Based on this learning from the second round of research, we’ll either capture some user needs, write some new hypotheses to test, create some further prototypes to test, or maybe a mixture of all three.
Side effects
One interesting side-effect of our research sessions that we noticed was that some users were unaware of some aspects of our existing service, and as @kev_c_murray pointed out, some users left the sessions with an increased knowledge of what is available to them.
With comments like “Yeah I’m definitely going to go and look that up on your site now.” – we’re actually driving a little bit of behaviour change through the research itself. Okay, so if this was our behaviour-change strategy we’d have to do another 7 million days of research to reach the whole UK adult population, but every little helps, right…
What have we learned about how we do User Research?
- The one week cycle of doing two full days of Research, then sorting and prototyping, is hard work. In fact it probably isn’t sustainable in the way we’re doing it right now, and we’ll need to adapt as we move into an Alpha phase.
- Do a proper sound check at the start of the day – in both facilities we’ve used we’ve had to adjust the mic configuration during or after the first interview.
- Research facilities do good lunches.
- The observers should make their own notes around specific insights and themes, but don’t have everyone duplicating the notes that the note-taker makes – you’ll just end up with an unmanageable mountain of post-its.
More please
 We plan to do much more of this as we continue to transform the NHS Choices service. As we move into an Alpha phase, we’ll continue to test what we’re building with users on a regular basis – we’ll probably switch from a one-week cycle to testing every fortnight.
We plan to do much more of this as we continue to transform the NHS Choices service. As we move into an Alpha phase, we’ll continue to test what we’re building with users on a regular basis – we’ll probably switch from a one-week cycle to testing every fortnight.
As someone from more of a Software Development background, I find it fascinating to be able to get even closer to users than I have before, and start to really understand the context and needs of those people who we’ll be building the service for.
If you’re interested in reading more around some of the ideas in this post, try Lean UX – it’s a quick read, and talks in more detail about integrating User Research into an agile delivery cycle.

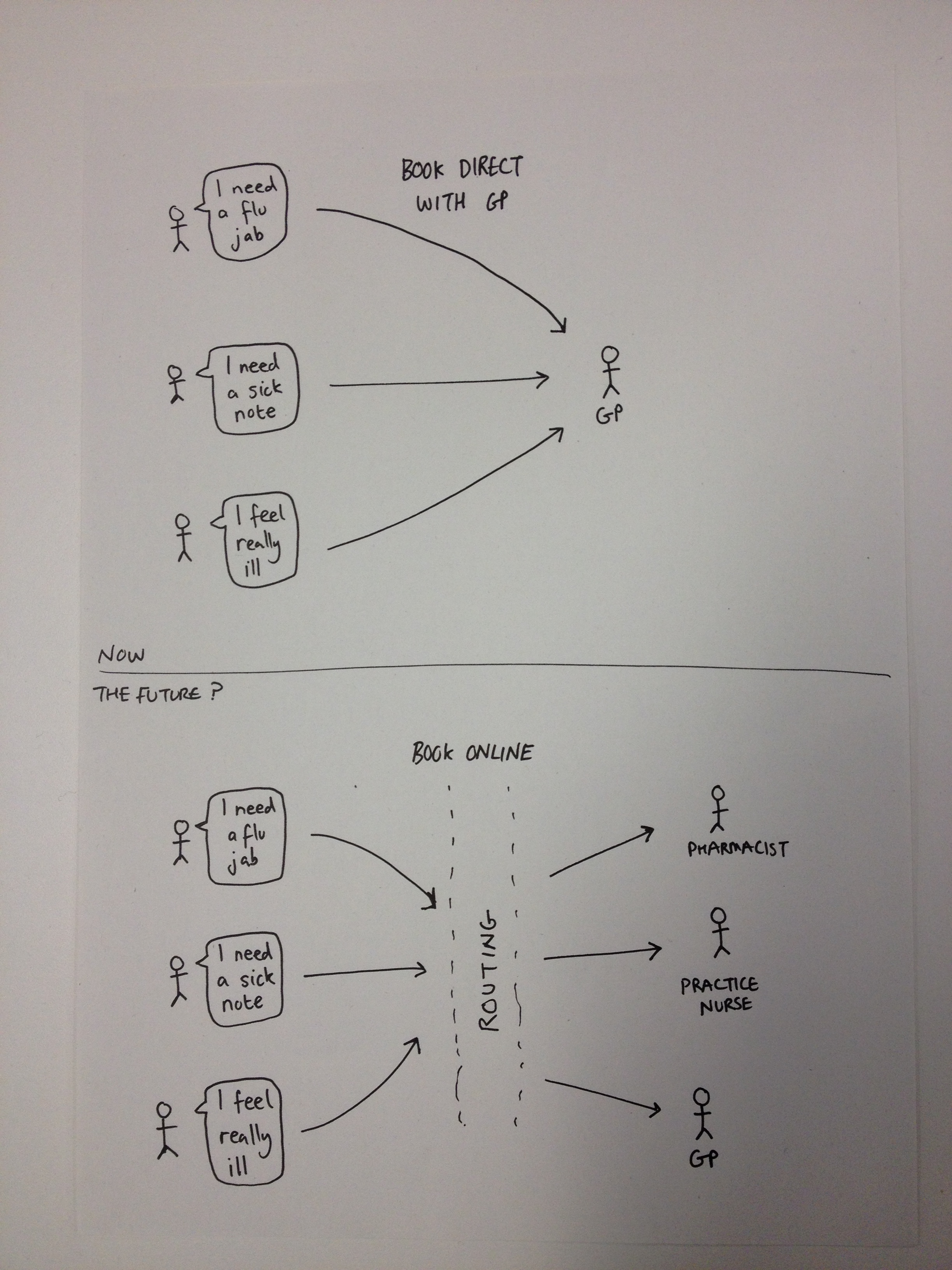






 it out since picking up a copy of
it out since picking up a copy of