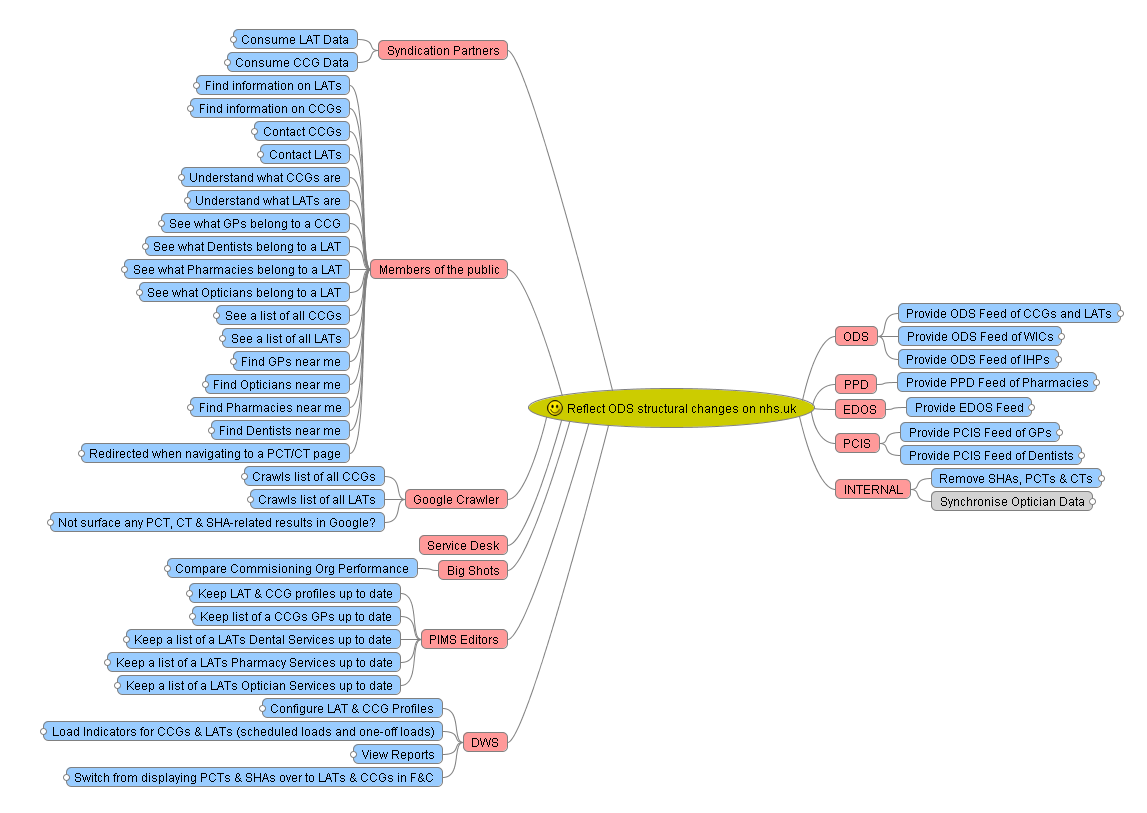
The story so far
Over the last few years we’ve tried a variety of estimation and planning techniques. We’ve suffered from our fair share of Estimation Anti-patterns and tried various approaches to avoid these.
I thought it’d be useful to outline some of the approaches we’ve tried, the problems we’ve encountered, and how we’ve reacted to those in order to get to where we are now.
2010
Back in 2010 estimates were forced to fit a previously agreed plan:
“What’s the estimate”
“60 days”
“It needs to be 30, go away and re-estimate it”
This is a cross between the Target Estimation and Comedy-driven Estimation anti-patterns, and obviously it’s just a big farce – what’s the point in estimating in the first place if you’re just going to have a fixed time, scope and resource all imposed on you.
This approach led to teams and individuals being put under a great deal of pressure, and generated bad feeling between the people who imposed the ‘estimates’ and those who had to stick to them.
Of course corners were cut in order to meet the fixed estimates, which led to further technical debt, which just exacerbated the whole problem for future projects – the Done-driven estimation anti-pattern.
2011
During 2011 we gradually moved away from ‘fixed’ estimates. We introduced a few fairly standard ideas –
Estimating in ideal days
We started estimating in ideal days, to take into account of the fact that a Developer doesn’t get to spend their entire day dedicated to the estimated item that they’re currently working on.
This worked okay, once we finally hammered out the exact definition of an ideal day…
“Does an ideal day include meetings?”
“But what if the meeting relates to the story they’re working on?”
Having the people who are going to do the work doing the estimation
We tried to throw out the idea that a single individual could estimate a project more accurately and precisely than the developers who were familiar with the codebase, and who were about to do the work.
Estimates would still be questioned by people who weren’t going to do the work. We’d get Architects or Managers questioning why Developers thought something would take, for example, 3 days –
“That story’s just a few lines of code isn’t it”
This was frustrating, and we probably did waste more than a few hours justifying estimates to people outside the team.
Planning poker to derive estimates from the group, not individuals
The introduction of planning poker was quite good fun to start with. It bought the team together and helped to alleviate some of the discussions and justification that we had to go through.

However, it sometimes did feel like a bit like a negotiation – with some people deliberately going in low to try to bring an estimate down.
Velocity – planning based on past performance
We introduced the standard idea of velocity from Scrum –
Take the number of ideal days you complete in an iteration, and then plan your next iterations based on that.
This was sound, but unfortunately it was described by whoever sold the concept to senior management as being a percentage measure. So if a team got 30 ideal days of stories completed in an iteration of 40 elapsed developer-days, the team had achieved a ‘75% velocity’ – this was really ugly, and came to hurt us, as you’ll read below.
We struggled a bit with the idea of the team committing to a sprint goal. There were a lot of dependencies on other teams that we just didn’t account for, so we could never really meet what felt like reasonable goals.
Relative Estimates

We started to estimate work based on it’s relative size, compared to work we’d done previously. After all, this seemed like the quickest and generally most reliable way to estimate. If you ask a decorator to quote for painting a room, they can usually give you a rough quote without measuring up, because they’ve already painted lots of rooms of roughly the same size before.
This approach for us was pretty successful – if we’d tackled a similar size project in the same product area, we could look up the actual effort we expended on the previous project and use that to guide our estimate for the new project. When the newer project was complete, looking at the actuals showed us that this was a fairly accurate method.
It helped us to resolve the Fractal Estimation anti-pattern that we’d suffered from in the past, because we were now looking at sizing the project as a whole to start with, as opposed to trying to break it up and estimate each constituent part.
The problem was when we had to estimate something that wasn’t really similar to anything we’d built before.
Overall things improved during 2011 – the people doing the work had more control, and we had a method by which to size things, and plan work. But then things started to unravel…
2012
It gradually became clear that some of the things that we thought were working, weren’t really…
Story Points
The business didn’t understand the concept of Ideal days, so we re-branded them as Story Points, where a story point equates to an ideal day. This didn’t really help though as we never built a shared understanding that Story Points are a relative measure of size, as opposed to an exact measure of time taken to do something.
“How big is the project?”
“30 points”
“You have five developers, so it’ll be done in six days?”
“Erm…maybe…”
What’s velocity?
The concept of Velocity was never been well understood by the business either. It became seen as a measure of efficiency, or utilisation. To paraphrase:
Managing Director: “What’s velocity?”
Programme Manager: “It’s the time that developers aren’t working – like when they go for lunch or a p*ss”
and so the percentage thing came back to bite us – velocity was used as a stick to beat the teams with –
“The Developers are only working at 60%, we need to get them to work at 70%”
Targets
 We moved away from planning based on past performance and trying to improve on that, to planning based on fixed targets per developer. The Target Estimation anti-pattern again.
We moved away from planning based on past performance and trying to improve on that, to planning based on fixed targets per developer. The Target Estimation anti-pattern again.
To increase speed; targets were set for developers to develop a certain amount of work each week.
The planning was based on one big resource pool of developers (only), with individual targets aggregating up into one giant target.
The focus was on individual developer productivity rather than actual throughput of developed and tested stories. This led to a bad working environment, much frustration, and undesirable behaviours.
Some teams adopted the Velocity-driven estimation anti-pattern in order to get around the targets they were set. But it didn’t mean they were delivering any more work – it just meant that Story Points became even more meaningless…
Budgets
A positive thing we introduced in 2012 was the idea of budgets for pieces of work. This was the starting point for turning the question around and establishing what each piece of work is worth to the business –
“How long will this project take you?”
“We’re not sure yet. How long would you like us to spend working on it?”
Developers-only
As you’ll have picked up from the story so far – the vast majority of the focus was on Developers, and only Developers. They were widely regarded as the limiting ‘golden’ resource, and as such theirs was the only work that needed estimating – everything else that needed to be done like story-writing, deployment and testing would just fall into place.
This is partly the Done-done-driven Estimation anti-pattern. The problem with focussing on just Developers is that they cannot deliver work in isolation. There are many inter-dependencies on other roles such as BAs, EAs, Testers, Infrastructure, DBAs and so on.
It is the team that delivers work, not individuals. You can try to estimate the effort that a Developer alone will have to put in to deliver a story, but that really is only a part of the work needed to deliver end-to-end.
2013
As part of the more focussed agile transformation process, we decided to have a complete re-think about how we estimate and plan at the team-level.
Principles
We came up with some principles by which we wanted to base our estimation and planning. These are based on the experience of the team, and tied in with the feedback that we received from some external consultants we were working with.
- Plan based on past performance
- Track the whole cycle, not just development
- Estimates are not exact quotes
- Plan at a team level and scale up, not the other way around
- Limit work in progress
- Separate the methodologies used for planning, from that used for performance management
What matters
We considered having another crack at using story point estimation and velocity as it was intended, but decided that there were already too many misconceptions around this for it to be a success.
Instead we opted to try some of the more empirical techniques associated with Kanban, which tied in nicely with our move away from iterations to more of a flow-based delivery model.
The beauty of these techniques is that they focus on what matters – the question that our colleagues and management want an answer to is generally
“When will we get this product?”
not
“How much effort will it take?”
We started focussing on the elapsed time that it took to deliver things, as opposed to how much effort a particular role puts in to get it there.
Efficiency
An eye-opening aspect of this is to look at Business Process Efficiency (BPE) – which is the ratio of the time that a piece of work is actively being worked on (by anyone), to the total time that it takes to deliver that piece of work.
Many organisation are working with a typical BPE of just 15%. So for the vast majority of the time it takes to deliver something, that thing is just sat waiting to be worked on – perhaps at a handover between roles or teams. So all the work we put in to estimate effort was really only focussed on a very small portion of the time it takes to deliver – and focussing on developers only magnified this even more!
The here and now
Flow and Forecasting
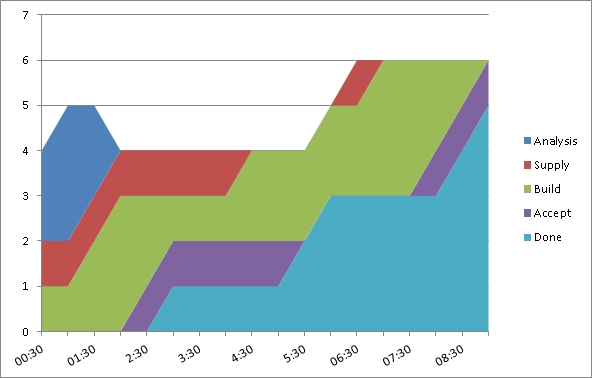
Where we are now is that the teams aim to split stories up nice and small. They then count the number of stories in each state of their kanban system each day. We use this to track each teams’ flow.
We generate Cumulative Flow Diagrams (CFD) and record team throughput. Both of these can be used to forecast future delivery. The great part is that this is not based on anyone’s judgement of the size of a piece of work – it is based on the actual empirical figures for how long it takes to deliver.
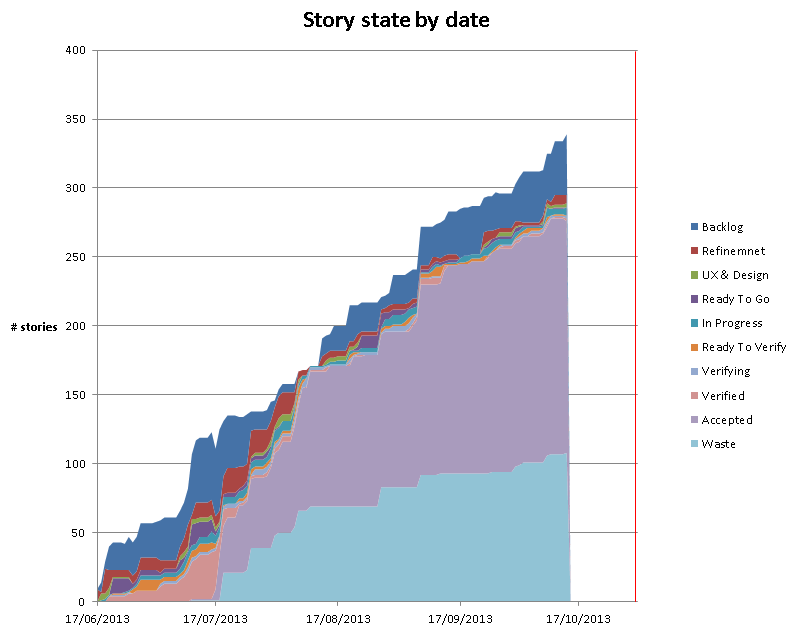
Cycle Time
We track the Cycle Time for stories – this is the time it takes to deliver a story end-to-end. It is currently surprisingly high, and we’re challenging teams to see what they can do to reduce their cycle times – the quickest win for this is to reduce the time that stories sit in a particular state waiting for someone to pull them into the next. We can improve on this by limiting the number of things that we work on at any one time.
Sizing
When we set out with this method of using empirical data to forecast, instead of estimating, we were concerned about the disparity in the size of stories. If we’re just counting stories what would happen if we delivered all of the smaller stories first, and were left with all the bigger ones – it’d look like we were way further head than we really were.
To counter this we sized stories small, medium or large. We had one person per team doing this to generate some consistency, and it was a quick process that was done as part of the story’s refinement.
We then tracked CFDs for both story count, and a kind of ‘weighted count’ that took the relative size into account e.g. a medium is twice a small, and a large is twice a medium.
So this took differences in story size into account, but what we found was that over time the slope of the CFD’s accepted state was roughly the same for the weighted and non-weighted count. A forecast based on story count alone should be as accurate as the forecast that takes story size into account.
For this reason, we’ve stopped sizing altogether and now just count stories. What’s key is that we aim to get a reasonable consistency of small stories.
Time-boxes
Back when we introduced budgets we started to turn around the question of how long something would take, to how long did the business want us to spend on it – what is it worth?
We’ve extended this to reinforce the idea of fixing time and flexing scope, by planning time-boxes. A project has an assigned delivery time-box during which the team pull stories from the backlog for that project. Once that time-box is over the team finish any unfinished stories off, but start pulling new stories from the next project time-box to which they’re assigned. Essentially the time-box controls which project the team pull new stories from – or in Kanban terms – where they replenish their system from.
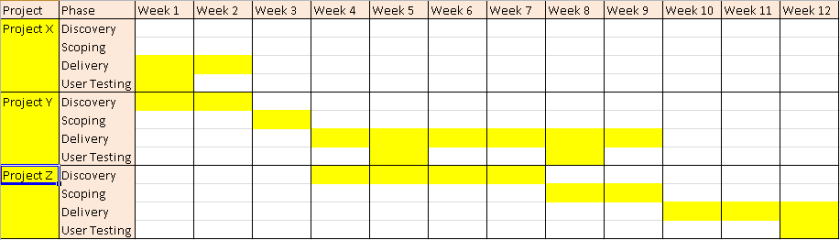
Project cycle-time
The question that remains is what is a reasonable length of time-box to plan in for a project.
At a higher-level what we need to do next is start tracking the cycle time of overall projects. We can then use this to plan sensible time-boxes for delivery of future projects of a similar nature.
The Future
It’s been a long and sometimes frustrating journey – but it feels like we are now in a better place. We now spend a lot less time sizing and estimating things – practically none in fact.
In future we aim to widen the gathering of metrics look for further patterns to see what impacts on delivery. There are still challenges ahead as we embark on newer, bigger pieces of work, but I think we are better equipped to give honest, accurate forecasts of what can be delivered, and by when.
PS. If you’d asked me to estimate how long it’d take me to write this blog post I’d have said a couple of days. It took a bit longer…
photo credit: lemonad via photopin cc
photo credit: eatmorechips cc
photo credit: bensutherland cc







 We plan to do much more of this as we continue to transform the NHS Choices service. As we move into an
We plan to do much more of this as we continue to transform the NHS Choices service. As we move into an 









 it out since picking up a copy of
it out since picking up a copy of